
👋 Hey there! This video is for members only.
Please log in or create a free account below.
Login / Sign Up
Hello and welcome back to the blog!
In today’s post, we’re diving into one of the newest features in Databricks: SQL Stored Procedures. This feature was released just a few weeks ago, and it’s a game-changer for anyone who’s been waiting for more SQL Server–like functionality inside Databricks.
We’ll walk through:
- What stored procedures are in general
- How Databricks implements them (including IN, OUT, and INOUT parameters)
- How permissions work with
SQL SECURITY INVOKER - A demo with sample data and reusable procedures
- Extra commands (
SHOW,DESCRIBE,DROP) you can use - How stored procedures show up in the Databricks catalog
🔹 What Are Stored Procedures?
If you’ve used SQL Server (or any relational database), you’ve likely worked with stored procedures before.
A stored procedure is essentially reusable SQL code that you can call again and again, rather than rewriting the same query.
Some key benefits:
- You can parameterize procedures (e.g., pass in a
customer_id) - They help with cleaner, reusable SQL workloads
- Great for ETL pipelines (data cleaning, logging, transformations, etc.)
- Now available natively in Databricks! 🎉
🔹 IN, OUT, and INOUT Parameters
Databricks stored procedures support three types of parameters:
- IN: Passes a value into the procedure (e.g.,
customer_id) - OUT: Returns a value from the procedure (e.g., a computed total)
- INOUT: Both accepts an input and returns an updated value
Example (simplified):
CREATE OR REPLACE PROCEDURE area_of_rectangle
(
IN x INT, -- length
IN y INT, -- width
OUT area INT, -- returns calculated area
INOUT acc INT -- accumulator across calls
)
LANGUAGE SQL
SQL SECURITY INVOKER
AS
BEGIN
SET area = x * y;
SET acc = acc + area;
END;
🔹 What is SQL SECURITY INVOKER?
When you create a stored procedure in Databricks, you’ll notice this clause:
SQL SECURITY INVOKER
This means the procedure runs with the privileges of the caller, not just the creator.
- If you create the procedure, others can run it with their own privileges.
- Useful for security, but also something to think about — you don’t always want everyone running procedures that modify production data.
- Expect more granular security controls from Databricks in future updates.
🔹 Demo: Building a Data Cleaning Stored Procedure
Let’s go through a simple example:
1. Create Raw, Clean, and Log Tables
-- Raw table (Bronze layer in Medallion architecture)
CREATE OR REPLACE TABLE sales_raw (
sale_id INT, sale_date_str STRING, customer_id STRING,
amount DECIMAL(10,2), origin STRING
);
-- Clean table (Silver layer)
CREATE OR REPLACE TABLE sales_clean (
sale_id INT, sale_date DATE, customer_id STRING,
amount DECIMAL(10,2), origin STRING
);
-- ETL log table
CREATE OR REPLACE TABLE etl_log (
etl_timestamp TIMESTAMP, date_from DATE, date_to DATE, origin STRING
);
-- Insert dummy data
INSERT INTO sales_raw VALUES
(1, '2025-07-29 ', ' C001 ', 100.50, ' mobileApp '),
(2, '2025-07-30', 'C002', 200.75, 'web'),
(3, '2025-08-01', 'C003 ', 50.00, 'mobileApp');
2. Create the Stored Procedure
CREATE OR REPLACE PROCEDURE etl_load_sales_by_range_and_source (
IN p_start_date DATE, IN p_end_date DATE, IN p_origin STRING
)
LANGUAGE SQL
SQL SECURITY INVOKER
AS
BEGIN
DECLARE run_timestamp TIMESTAMP DEFAULT CURRENT_TIMESTAMP();
-- Clean and insert into sales_clean
INSERT INTO sales_clean
SELECT
sale_id,
CAST(TRIM(sale_date_str) AS DATE),
TRIM(customer_id),
amount,
TRIM(origin)
FROM sales_raw
WHERE CAST(TRIM(sale_date_str) AS DATE) BETWEEN p_start_date AND p_end_date
AND TRIM(origin) = p_origin;
-- Log ETL run
INSERT INTO etl_log VALUES (run_timestamp, p_start_date, p_end_date, p_origin);
END;
3. Call the Procedure
CALL etl_load_sales_by_range_and_source(date('2025-07-28'), date('2025-08-01'), 'mobileApp');
4. Verify Results
-- Raw Data
SELECT * FROM sales_raw;
-- Cleaned Data
SELECT * FROM sales_clean;
-- Log
SELECT * FROM etl_log;
🔹 Other Commands You Can Use
Databricks has also introduced supporting commands for managing stored procedures:
-- Show all procedures in schema
SHOW PROCEDURES;
-- Describe a specific procedure
DESCRIBE PROCEDURE etl_load_sales_by_range_and_source;
-- Drop a procedure
DROP PROCEDURE etl_load_sales_by_range_and_source;
🔹 Stored Procedures in the Catalog
Once created, your stored procedures also show up in the Databricks Catalog. Interestingly, they’re currently grouped under Functions rather than a separate “Stored Procedures” section.
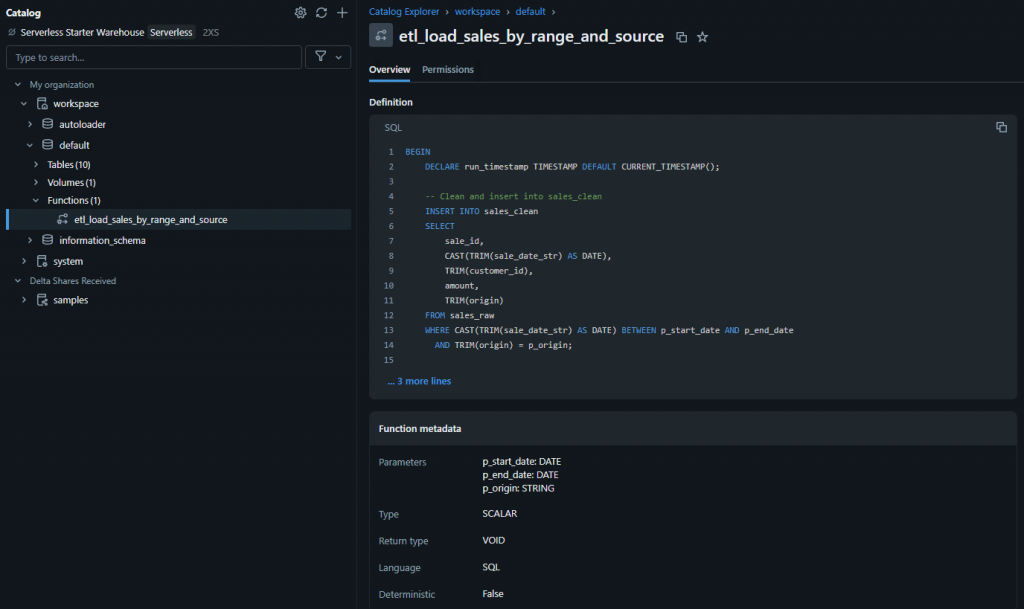
This is slightly different from SQL Server conventions, but still a nice way to manage and lock them down with Unity Catalog permissions.
✅ Conclusion
Databricks introducing SQL Stored Procedures is a huge step forward:
- Reusable, parameterized SQL code
- Built-in support for IN, OUT, and INOUT parameters
- Logging and ETL-style use cases now much simpler
- Manageable with
SHOW,DESCRIBE, andDROP - Integrated into the Databricks Catalog
While the security model (SQL SECURITY INVOKER) may need some refinement, this is a fantastic addition — especially for teams migrating workloads from SQL Server or simplifying SQL-heavy pipelines.
👉 Give them a try in your Databricks environment today and see how they can streamline your workflows!